Using pandas extensions to improve your EDA process
14 Jan 2023 || 16 minutes to read || : ml, pandas, python ||A few years ago I learned that you can extend the pandas library with your own methods, and this has been a real game-changer for the way I think about my pandas utilities. Essentially, a pandas “extension” is the process of adding your own namespace to pandas objects, such as Series and DataFrame objects. This allows you to access the methods on that namespace when you reference the object. One such example that comes baked into the library is the str namespace, accessible via pd.Series.str, which gives you access to a broad range of vectorized string functions on Series and Index objects.
It turns out that it is quite easy to make your own pandas extensions. In the past, my extensions have included an nlp library for NLP-related functions, a prep library for basic preprocessing techniques I use on a regular basis, a stat library for basic statistical techniques and analysis functions, and more. I’ve also had a lot of fun seeing what else others have created using this approach. One of my all-time favorite libraries for extending pandas is pyjanitor, and my appreciation for this package is two-fold – for one thing, it has most of the basic functions you’d need when it comes to preprocessing and analyzing your data with pandas, and for another, it provides an API that is explicitly verb-based and geared toward a cleaner method-chaining approach, similar to R’s dplyr package.
If any of this piques your interest, read on to see a basic example of an eda extension, which can be made accessible by any pandas DataFrame.
The eda accessor
The key to creating your first accessor (i.e. your namespace) will be the register_dataframe_accessor decorator, available straight from the pandas API. Using this decorator, we can start by setting up the basic structure of the accessor:
import pandas as pd
from pandas.api.extensions import register_dataframe_accessor
@register_dataframe_accessor("eda")
class EDA:
def __init__(self, df):
self._validate(df)
self._obj = df
@staticmethod
def _validate(obj):
# verify this is a DataFrame
if not isinstance(obj, pd.DataFrame):
raise AttributeError("Must be a pandas DataFrame")
The important thing to keep in mind moving forward is that, for a DataFrame accessor, each function will expect a DataFrame object as the first argument. Every argument after that can be whatever you want. The same goes for any Series accessor, the first argument expected would be a Series object (the Series accessor decorator is also available from the pandas API at pandas.api.extensions.register_series_accessor).
We will start with a simple example: returning different dtypes in a DataFrame. Let’s extend our accessor like so:
import numpy as np
import pandas as pd
from pandas.api.extensions import register_dataframe_accessor
@register_dataframe_accessor("eda")
class EDA:
def __init__(self, df):
self._validate(df)
self._obj = df
@staticmethod
def _validate(obj):
# verify this is a DataFrame
if not isinstance(obj, pd.DataFrame):
raise AttributeError("Must be a pandas DataFrame")
@staticmethod
def _get_columns(type):
if type == 'numerics':
return [np.number]
elif type == 'dates':
return [np.datetime64]
elif type == 'categories':
return ['object', 'category']
else:
raise ValueError("Type not recognized! Choose one of: 'numerics', 'dates', 'categories'")
def types(self, type):
return self._obj.select_dtypes(include=self._get_columns(type)).columns.tolist()
def categories(self):
return self._obj.select_dtypes(include=['object', 'category'])
def numerics(self):
return self._obj.select_dtypes(include=[np.number])
def dates(self):
return self._obj.select_dtypes(include=[np.datetime64])
Running this in a cell of a Jupyter notebook, we can test our structure so far with a bit of basic data
df = pd.DataFrame({"a": [0, 1, 2], "b": [5, 6, 7], "c": ['yes', 'yes', 'no']})
And then we can call our eda accessor like this to subset the DataFrame to only the categorical types:

Alternatively, we can run
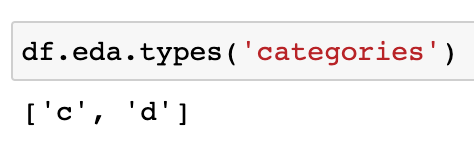
to output a list of the categorical columns. The same can be done for numerics and dates using these methods.
We can also add on helper methods for easy cleaning, summarizing, and plotting. For this next example, we will add in two functions: one for dropping columns where the number of NaN values exceeds a certain percentage threshold, and another for summarizing frequency counts. We can add these methods to the accessor like this:
# code truncated for readibility
@register_dataframe_accessor("eda")
class EDA:
...
def drop_missing(self, pct=99):
missing_pct = (self._obj.isna().sum() / self._obj.shape[0]) * 100
dropped_cols = missing_pct[missing_pct.values >= pct].index
print(f"Dropped {list(dropped_cols)}")
self._obj = self._obj.drop(cols_2_drop, axis=1)
return self._obj
def counts(self, col):
freq_counts = pd.DataFrame(self._obj[col].value_counts())
freq_counts.columns = ['freq']
freq_pct = pd.DataFrame(self._obj[col].value_counts(normalize=True)*100)
freq_pct.columns = ['pct']
freq_pct.pct = round(freq_pct.pct, 2)
freq_df = pd.merge(freq_counts, freq_pct, left_index=True, right_index=True)
freq_df[col] = freq_counts.index
freq_df = freq_df[[col, 'freq', 'pct']]
freq_df.reset_index(inplace=True, drop=True)
return freq_df
For demonstration purposes, let’s extend our test DataFrame to have a completely null column
df = pd.DataFrame({"a": [0, 1, 2], "b": [5, 6, 7], "c": ['yes', 'yes', 'no'], "d": [np.nan, np.nan, np.nan]})
And if we run df.eda.drop_missing(), we see that column d is appropriately removed for having all NaN values:

Then, if we want to see the frequency counts of a column, we can do so with this new counts function:

You can continue adding in functions like these ad infinitum to your accessor (click here to grab the full code above on GitHub). For example, you could add in your own functions for measuring skew, advanced summary statistics, capturing the top K values, and more. The EDA accessor is also a good place for adding in your more complex or frequently-used plotting functions. One library I like to use for general-purpose functions that could easily be added to an accessor like this is the datasist library, or alternatively you can gain inspiration from traceml’s library of processors. I’ve also liked using more advanced EDA profilers and functions and wrapping my EDA functions around those – the dataprep.eda package offers some of my favorite functions for this purpose.
Creating methods outside of a namespace
You can also register methods outside of a namespace and call them directly on your DataFrame or Series. This is especially nice for method chaining, as seen from this example in the pyjanitor repo:
df = (
pd.DataFrame.from_dict(company_sales)
.remove_columns(["Company1"])
.dropna(subset=["Company2", "Company3"])
.rename_column("Company2", "Amazon")
.rename_column("Company3", "Facebook")
.add_column("Google", [450.0, 550.0, 800.0])
)
The way to add your own methods to a DataFrame or a Series is slightly more complicated, but made simple using the pandas-flavor library. You can install that library yourself, or you can just copy the relevant portion of the code and add it to your own importable module:
from functools import wraps
from pandas.api.extensions import register_series_accessor, register_dataframe_accessor
def register_dataframe_method(method):
"""Register a function as a method attached to the Pandas DataFrame.
Example
-------
.. code-block:: python
@register_dataframe_method
def print_column(df, col):
'''Print the dataframe column given'''
print(df[col])
"""
def inner(*args, **kwargs):
class AccessorMethod(object):
def __init__(self, pandas_obj):
self._obj = pandas_obj
@wraps(method)
def __call__(self, *args, **kwargs):
return method(self._obj, *args, **kwargs)
register_dataframe_accessor(method.__name__)(AccessorMethod)
return method
return inner()
def register_series_method(method):
"""Register a function as a method attached to the Pandas Series."""
def inner(*args, **kwargs):
class AccessorMethod(object):
__doc__ = method.__doc__
def __init__(self, pandas_obj):
self._obj = pandas_obj
@wraps(method)
def __call__(self, *args, **kwargs):
return method(self._obj, *args, **kwargs)
register_series_accessor(method.__name__)(AccessorMethod)
return method
return inner()
Then, if you decorate your desired method with one of these decorators like so (example taken from pyjanitor)…
@register_dataframe_method
def shuffle(df: pd.DataFrame, random_state=None,
reset_index: bool = True) -> pd.DataFrame:
result = df.sample(frac=1, random_state=random_state)
if reset_index:
result = result.reset_index(drop=True)
return result
…you can then access your method directly on the object (in this case, a DataFrame object) instead of through a namespace.
Before:

After:

Summing it all up
In summary, pandas extensions are a great way to develop custom data types and namespaces that allow you to add your own functions and accessors to pandas objects. And it doesn’t just stop at EDA – here are some other libraries that I have seen do cool things with pandas extensions.
-
pyjanitor- the ultimate library of verb-based methods worth adding to any DataFrame or Series object -
pandas-selectable- aselectaccessor that provides tab-completion to the traditional pandasqueryfunction -
pandas-log- a logging accessor that provides feedback about pandas function operations, similar to R’stidylogpackage -
pdvega- an accessor that allows you to quickly create Vega-Lite plots in your Jupyter notebook -
cyberpandas- though this post didn’t address theExtensionArray, this module provides a good example of its use, creating an extension allowing users to store IP and MAC address data inside the pandas DataFrame
Have fun extending pandas, and please let me know if you end up doing anything cool with this. :)